RuntimeError: mat1 and mat2 shapes cannot be multiplied (800x1600 and 800x9922) |
您所在的位置:网站首页 › tochca t › RuntimeError: mat1 and mat2 shapes cannot be multiplied (800x1600 and 800x9922) |
RuntimeError: mat1 and mat2 shapes cannot be multiplied (800x1600 and 800x9922)
|
Hi, I am trying to do language modelling with Pytorch and am having issues with my model. train_iter = PennTreebank(split='train') tokenizer = get_tokenizer('basic_english') vocab = torchtext.vocab.build_vocab_from_iterator(map(tokenizer, train_iter), specials=['']) vocab.set_default_index(vocab['']) def data_process(raw_text_iter: dataset.IterableDataset) -> Tensor: data = [torch.tensor(vocab(tokenizer(item)), dtype=torch.long) for item in raw_text_iter] return torch.cat(tuple(filter(lambda t: t.numel() > 0, data))) train_iter, val_iter, test_iter = PennTreebank() train_data= data_process(train_iter) val_data= data_process(val_iter) test_data= data_process(test_iter) def batchify(data: Tensor, bsz: int) -> Tensor: seq_len = data.size(0) // bsz data = data[:seq_len * bsz] data = data.view(bsz, seq_len).t().contiguous() return data.to(device) batch_size = 80 eval_batch_size = 80 train_data = batchify(train_data, batch_size) # shape [seq_len, batch_size] val_data = batchify(val_data, eval_batch_size) test_data = batchify(test_data, eval_batch_size) class LSTM(nn.Module): def __init__(self, vocab_size, embedding_dim, hidden_dim, num_layers, dropout_rate, tie_weights): super().__init__() self.num_layers = num_layers self.hidden_dim = hidden_dim self.embedding_dim = embedding_dim self.batch_size = batch_size self.embedding = nn.Embedding(vocab_size, embedding_dim) self.bilstm = nn.LSTM(embedding_dim, hidden_dim, num_layers=num_layers, dropout=dropout_rate, bidirectional=True, batch_first=True) self.dropout = nn.Dropout(dropout_rate) self.linear = nn.Linear(hidden_dim, vocab_size) if tie_weights: assert embedding_dim == hidden_dim, 'cannot tie, check dims' self.linear.weight = self.embedding.weight self.init_weights() def forward(self, x, hidden): # x is a batch of input sequences x = self.embedding(x) x, hidden = self.bilstm(x, hidden) x = self.dropout(x) pred = self.linear(x) return pred, hidden def init_weights(self): init_range_emb = 0.1 init_range_other = 1/math.sqrt(self.hidden_dim) self.embedding.weight.data.uniform_(-init_range_emb, init_range_emb) self.linear.weight.data.uniform_(-init_range_other, init_range_other) self.linear.bias.data.zero_() for i in range(self.num_layers): self.bilstm.all_weights[i][0] = torch.FloatTensor(self.embedding_dim, self.hidden_dim).uniform_(-init_range_other, init_range_other) self.bilstm.all_weights[i][1] = torch.FloatTensor(self.hidden_dim, self.hidden_dim).uniform_(-init_range_other, init_range_other) def init_hidden(self, batch_size): h = torch.zeros(self.num_layers*2, batch_size, self.hidden_dim) c = torch.zeros(self.num_layers*2, batch_size, self.hidden_dim) return h, c vocab_size = len(vocab) embedding_dim = 800 hidden_dim = 800 num_layers = 2 dropout_rate = 0.4 tie_weights = True model = LSTM(vocab_size, embedding_dim, hidden_dim, num_layers, dropout_rate, tie_weights) model.to(device) import copy import time criterion = nn.CrossEntropyLoss() lr = 20.0 # learning rate optimizer = torch.optim.SGD(model.parameters(), lr=lr) scheduler = torch.optim.lr_scheduler.StepLR(optimizer, 1.0, gamma=0.95) def train(model: nn.Module) -> None: model.train() # turn on train mode total_loss = 0. log_interval = 200 start_time = time.time() hidden = model.init_hidden(batch_size) num_batches = len(train_data) // bptt for batch, i in enumerate(range(0, train_data.size(0) - 1, bptt)): data, targets = get_batch(train_data, i) seq_len = data.size(0) output, hidden = model(data, hidden) loss = criterion(output.view(-1, vocab_size), targets) optimizer.zero_grad() loss.backward() torch.nn.utils.clip_grad_norm_(model.parameters(), 0.5) optimizer.step() total_loss += loss.item() if batch % log_interval == 0 and batch > 0: lr = scheduler.get_last_lr()[0] ms_per_batch = (time.time() - start_time) * 1000 / log_interval cur_loss = total_loss / log_interval ppl = math.exp(cur_loss) print(f'| epoch {epoch:3d} | {batch:5d}/{num_batches:5d} batches | ' f'lr {lr:02.2f} | ms/batch {ms_per_batch:5.2f} | ' f'loss {cur_loss:5.2f} | ppl {ppl:8.2f}') total_loss = 0 start_time = time.time() best_val_loss = float('inf') epochs = 50 best_model = None for epoch in range(1, epochs + 1): epoch_start_time = time.time() train(model) val_loss = evaluate(model, val_data) val_ppl = math.exp(val_loss) elapsed = time.time() - epoch_start_time print('-' * 89) print(f'| end of epoch {epoch:3d} | time: {elapsed:5.2f}s | ' f'valid loss {val_loss:5.2f} | valid ppl {val_ppl:8.2f}') print('-' * 89) if val_loss < best_val_loss: best_val_loss = val_loss best_model = copy.deepcopy(model) scheduler.step()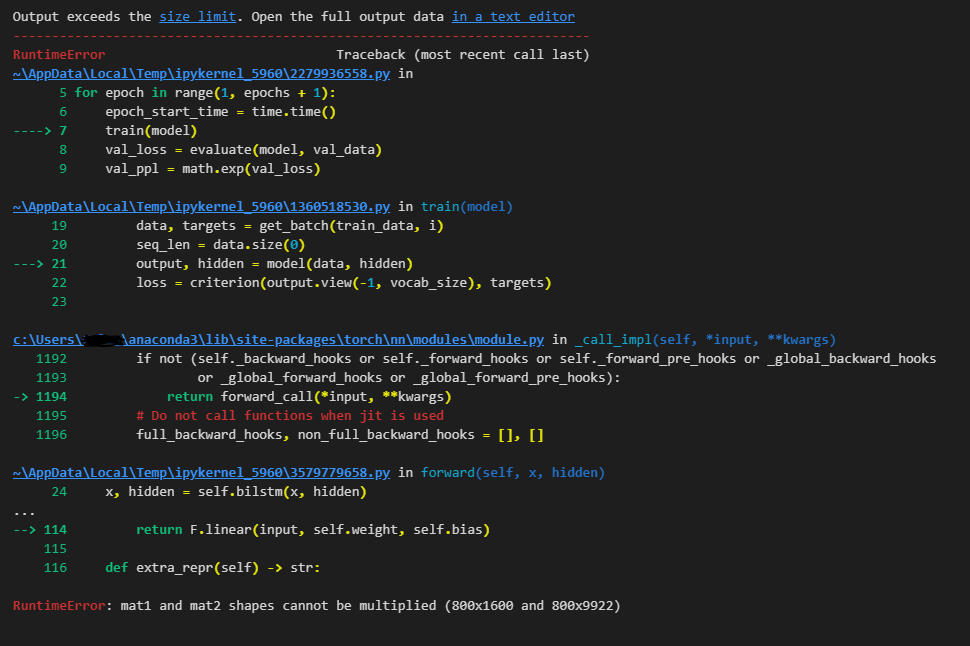 image970×646 26.1 KB
image970×646 26.1 KB
I am not very experienced with Pytorch but I believe the issue relates the dimensions of the model but I have no idea how to fix the issue. Any help is appreciated. |
【本文地址】